6.4 Split-apply-combine

Muchos problemas de análisis de datos involucran la aplicación de la estrategia split-apply-combine (Hadley Whickam, 2011). Esto se traduce en realizar filtros, cálculos y agregación de datos.
Split-apply-combine
- Separa la base de datos original.
- Aplica funciones a cada subconjunto.
- Combina los resultados en una nueva base de datos.
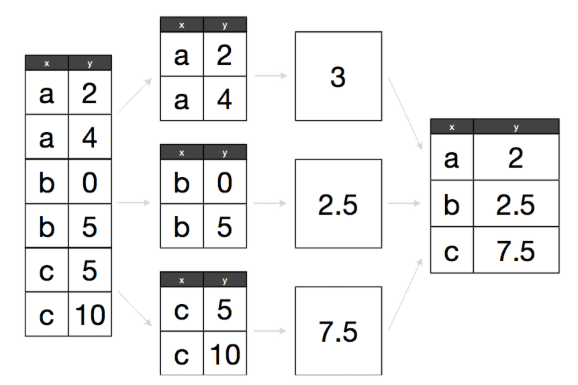
Cuando pensamos como implementar la estrategia divide-aplica-combina es natural pensar en iteraciones para recorrer cada grupo de interés y aplicar las funciones.
dplyr que contiene funciones que facilitan la implementación de la estrategia.
En este taller se estudiarán las siguientes funciones de la librería dplyr:
- filter: obtiene un subconjunto de las filas de acuerdo a una condición.
- select: selecciona columnas de acuerdo al nombre.
- arrange: re ordena las filas.
- mutate: agrega nuevas variables.
- summarise: reduce variables a valores (crear nuevas bases de datos).
Para mostrar las funciones se usará el siguiente dataframe.
df_ej <- data.frame(genero = c("mujer", "hombre", "mujer", "mujer", "hombre"),
estatura = c(1.65, 1.80, 1.70, 1.60, 1.67))
df_ej## genero estatura
## 1 mujer 1.65
## 2 hombre 1.80
## 3 mujer 1.70
## 4 mujer 1.60
## 5 hombre 1.67Filtrar
Filtrar una base de datos dependiendo de una condición requiere la función filter() que tiene los siguientes argumentos dplyr::filter(data, condition).
df_ej %>% filter(genero == "mujer")## genero estatura
## 1 mujer 1.65
## 2 mujer 1.70
## 3 mujer 1.60Seleccionar
Elegir columnas de un conjunto de datos se puede hacer con la función select() que tiene los siguientes argumentos dplyr::select(data, seq_variables).
df_ej %>% select(genero)## genero
## 1 mujer
## 2 hombre
## 3 mujer
## 4 mujer
## 5 hombreTambién, existen funciones que se usan exclusivamente en select():
starts_with(x, ignore.case = TRUE): los nombres empiezan con x.ends_with(x, ignore.case = TRUE): los nombres terminan con x.contains(x, ignore.case = TRUE): selecciona las variable que contengan x.matches(x, ignore.case = TRUE): selecciona las variable que igualen la expresión regular x.num_range("x", 1:5, width = 2): selecciona las variables (numéricamente) de x01 a x05.one_of("x", "y", "z"): selecciona las variables que estén en un vector de caracteres.everything(): selecciona todas las variables.
Por ejemplo:
df_ej %>% select(starts_with("g"))## genero
## 1 mujer
## 2 hombre
## 3 mujer
## 4 mujer
## 5 hombreArreglar
Arreglar u ordenar de acuerdo al valor de una o más variables es posible con la función arrange() que tiene los siguientes argumentos dplyr::arrange(data, variables_por_las_que_ordenar). La función desc() permite que se ordene de forma descendiente.
df_ej %>% arrange(desc(estatura))## genero estatura
## 1 hombre 1.80
## 2 mujer 1.70
## 3 hombre 1.67
## 4 mujer 1.65
## 5 mujer 1.60Mutar
Mutar consiste en crear nuevas variables con la función mutate() que tiene los siguientes argumentos dplyr::mutate(data, nuevas_variables = operaciones):
df_ej %>% mutate(estatura_cm = estatura * 100) ## genero estatura estatura_cm
## 1 mujer 1.65 165
## 2 hombre 1.80 180
## 3 mujer 1.70 170
## 4 mujer 1.60 160
## 5 hombre 1.67 167Resumir
Los resúmenes permiten crear nuevas bases de datos que son agregaciones de los datos originales.
La función summarise() permite realizar este resumen dplyr::summarise(data, nuevas_variables = operaciones):
df_ej %>% dplyr::summarise(promedio = mean(estatura))## promedio
## 1 1.684También es posible hacer resúmenes agrupando por variables determinadas de la base de datos. Pero, primero es necesario crear una base agrupada con la función group_by() con argumentos dplyr::group_by(data, add = variables_por_agrupar):
df_ej %>%
group_by(genero)## # A tibble: 5 x 2
## # Groups: genero [2]
## genero estatura
## <fctr> <dbl>
## 1 mujer 1.65
## 2 hombre 1.80
## 3 mujer 1.70
## 4 mujer 1.60
## 5 hombre 1.67Después se opera sobre cada grupo, creando un resumen a nivel grupo y uniendo los subconjuntos en una base nueva:
df_ej %>%
group_by(genero) %>%
dplyr::summarise(promedio = mean(estatura))## # A tibble: 2 x 2
## genero promedio
## <fctr> <dbl>
## 1 hombre 1.735
## 2 mujer 1.650